Transformer注意力机制详解
介绍
“自行车差点掉沟里,幸亏我把把把了把。”
“我用毒毒毒蛇会不会被毒毒死?”
刚送走一串“把”,又来了一串“毒”。
一个“毒”字,它既是名词,也是动词,还是形容词。就这么突兀地连在一起,为什么我们依然能毫不费力地看懂?
因为第一个“毒”在介词“用”后面,于是我们自然而然地把它理解成了名词;第二个“毒”在名词“毒”后面,自然就把他理解成了“动词”。
尽管可能并没有意识到,但我们在读每一个字时,注意力的焦点其实是不一样的。
人类理解语言是如此,AI也是如此。
这篇文章我们就用通俗易懂的语言,来聊聊现代AI模型中最重要、也是最不好理解的机制之一 —— 注意力机制 (Attention)。
嵌入 (Embedding)
首先我们需要意识到一点,人类在看到一个字的时候,看到的并不仅仅是这个字本身。
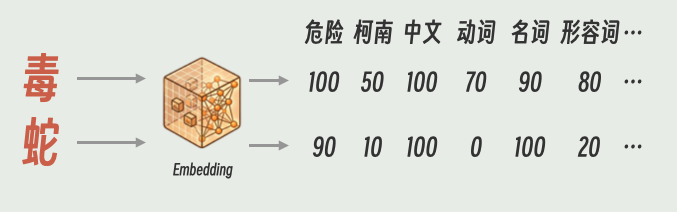
就比如“毒”。看到它时,我们会不自觉地调动知识储备给它贴标签:比如“危险的”、“柯南里经常出现的”、“无色无味的”、“杀人于无形的”。当然它的标签也可能是:它是中文、是动词、是名词、也是形容词。
总之,我们一切对“毒”这个概念的认识,都会被立刻贴到这个字上面。所以我们脑中处理的并不是“毒”这个字,而是这一系列概念的集合。
人们在设计大语言模型时,也是按照这种思路进行设计的。一个字进入大语言模型的第一步,就是概念分解并针对相关度打分,专业术语叫做Embedding(嵌入)。
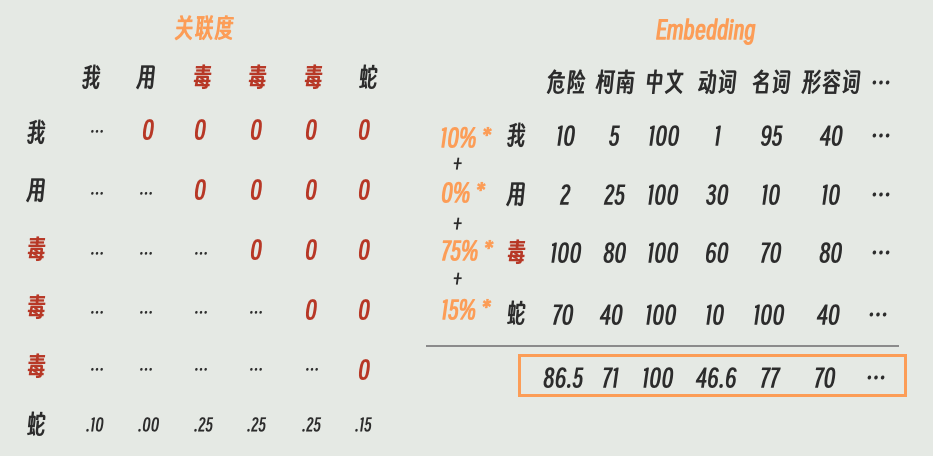
比如“毒”和“蛇”就可能被分解成
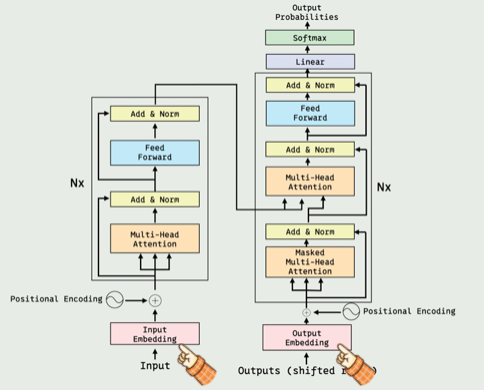
在Transformer架构中,Embedding对应的就是最下面这一步。
总之,Embedding之后,大语言模型处理的就不是“毒”和“蛇”了,而是代表了这两个字含义的数字集合 (向量)。
(注:为了方便理解,这里列举了具体的标签。在实际训练中,这些维度是模型自动学习的,我们通常无法解释每一维的具体含义。)
多头注意力(Multi-HeadAttention)
Embedding把隐含在字中的、混杂在一起的标签全都分离成了一列列的分数。这些分数就是注意力机制的原料。
注意力机制的主要作用是检测词与词之间的关联程度。不过,我们一般不会直接把Embedding放到Attention中去处理。因为它们太长了。古早的GPT-2的Embedding有1600个数字,DeepSeek有7168个。如果我们要检测一段话、一本书字与字之间的联系,直接使用高维向量会非常消耗算力。更麻烦的是,这些标签混杂了语法、语义、甚至“柯南”的剧情。假如我们要分析语法,混着柯南的信息一起看就会很乱。
所以我们希望把这些信息分门别类地整理好:一个Attention只负责处理语法,另一个Attention只负责追柯南。
这就叫做多头注意力机制(Multi-HeadAttention)。

我们还是以“我用毒毒毒蛇”为例。假如我们现在想关心的是语法,那我们就应该先把和语法相关的标签都提取出来。怎么实现呢?很简单,直接把整个Embedding放入线性层(LinearLayer)中。
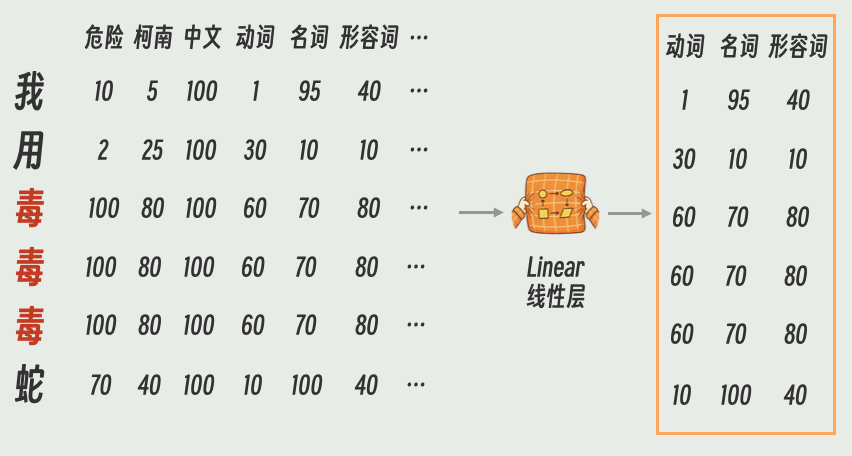
线性层是一切AI模型最基础的结构。在当前情况下,我们可以近似理解为:线性层把Embedding中和语法相关的标签提取了出来。想了解细节可以参考这篇文章(https://articles.zsxq.com/id_wttpd4wuxmjx.html)
提示:这只是一个方便理解的例子。实际模型中,线性层到底提取了什么特征,通常是“黑盒”的。
Q (Query) 与 K (Key)
刚刚我们提取的语法的特征矩阵,一般被叫做K(Key)矩阵。
那要怎么根据这些特征找词与词之间的关系呢?
其实还是打分。Key矩阵是根据词蕴藏的标签来打分的,得到了“语法表”。但这次打分内容是一个词对其它词的需求程度。
比如“蛇”字,作为一个名词,它经常和形容词出现在一起。所以它对形容词的需求分就很高。它偶尔和一个动词出现在一起,动词需求分就低一点。这个记录需求分数的矩阵叫做Q(Query)矩阵。

这个分数甚至还可以是负数,说明“蛇”是真的很不喜欢和某些词出现在一起。
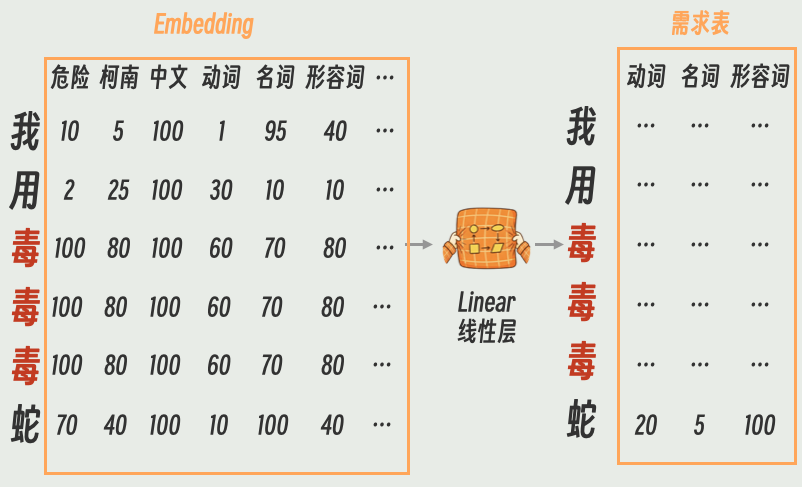
于是,我们有了新的小目标:除了语法表,我们还要再给每次个生成一个需求表
生成方法依然是使用线性层。输入是原始的 Embedding,经过变换输出就是Q矩阵。
- Key (K): 属性表。记录了每一个词是什么样的人(例如:我是形容词)。
- Query (Q): 需求表。记录了每一个词的择偶标准(例如:我找形容词)。
和K矩阵一样,生成方法依然是使用线性层。输入是原始的 Embedding,经过变换输出就是Q矩阵。
关联度计算(Q×K)
折腾了半天,现在让我们看看手里都有什么了。我们有一个“需求矩阵(Q)”,记录了每一个词的择偶标准;还有一个“语法矩阵(K)”,记录了每一个词的属性。那要怎么求词与词之间的关联度呢?其实就是向量乘法(点积)。比如我们要算“蛇”和“毒”的关联度:
“蛇”的需求(Q)中,形容词的分数很高。
“毒”的属性(K)中,形容词的分数也很高(“巧了,我就是形容词”)。

这两个高分一相乘,就会得到一个超级高的分数,直接拉高了整个结果。这反映了“蛇”与“毒”的高度关联。同理,我们可以计算“蛇”和其他所有字的关联度,还能把所有字之间的关联度都算一遍,就得到了一个字与字之间的关联度矩阵。

Mask (掩码)
这个关联度矩阵如果直接使用,就是Google BERT模型的架构。但我们经常用的GPT、Gemini这些聊天的大语言模型,还会做一步叫做 Mask的额外操作。
也就是把关联度矩阵右上角的所有数字都设置成负无穷。
为什么要这么做呢?因为大语言模型是“一个字一个字”生成的。比如当模型读到第一个“毒”字的时候,模型只知道前面有“我”和“用”,后面半句还没有出现。
所以第一个“毒”就只和前 2 个字以及它自己产生关联。我们把后面的关联分设为负无穷,确保模型在后续处理时,不会“偷看”到后面的答案。

Softmax
处理完成之后还有1个小问题:这些数字虽说代表了关联性,但它们本身并没有什么意义。所以科学家们又按照行,进行了一步叫做Softmax的操作。Softmax把这些杂乱的数字转换成了百分比。每一行加起来还正好是100%。而我们刚才设为负无穷的那些部分,经过Softmax就变成了0%。在实际工程中,为了防止分数过大导致梯度消失,科学家还会再除以一个系数——根号下标签的数量。在我们这个例子中标签数量是3,所以就除以根号3。

V (Value) 与 信息融合
就过Softmax之后我们就有了一个百分比表示的词与词之间的关注度了。
比如“蛇”对自己的关注度是 15%,对 3 个“毒”各自关注 25%,对“用”是 0%,对“我”是 10%。
那么接下来怎么做呢?
最简单的方法就是直接按照这个配方,把对应的向量拌在一起。
但是,我们这里不能直接用原始的 Embedding。为什么?因为原始 Embedding 维度太高了(包含了动词、名词、柯南等所有信息)。如果我们直接用它,计算量会非常大,而且混入了大量在这个 Head 中不关心的噪音(比如在分析语法时混入了柯南剧情)。
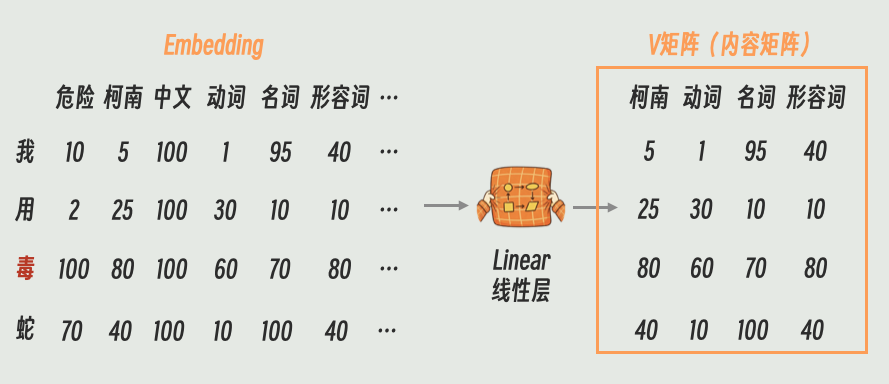
所以,和生成 K、Q 一样,我们也需要先对 Embedding 进行一次线性变换。
这次变换的目的主要是降维和特征提取 。我们希望把 Embedding 中和当前 Attention 目标(比如语法)不相关的信息过滤掉,只保留有用的精华。
变换后得到的这个矩阵,术语叫做Value(V) ,我们也可以叫它“内容矩阵”。
最后,我们用刚才计算出来的关注度百分比,去加权混合这个 V 矩阵中的向量。
这个新生成的向量里就包含了 10% 的“我”的 V、75% 的“毒”的 V 和 15% 的“蛇”的 V。
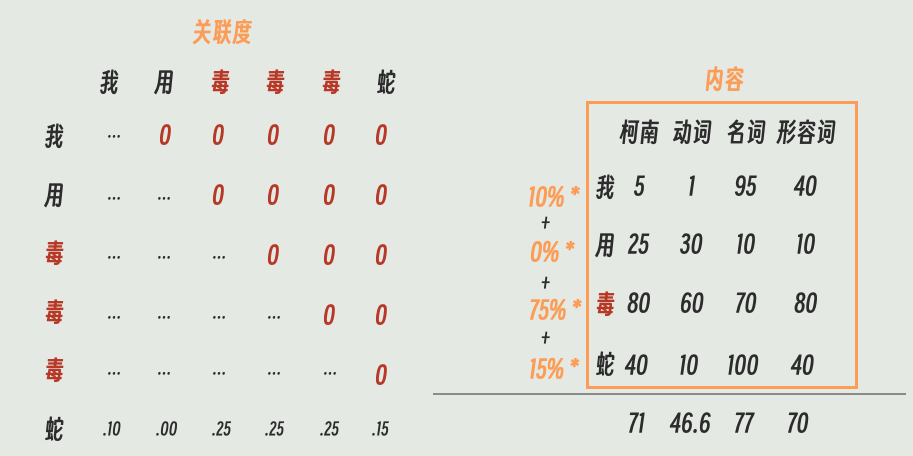
最终融合出来的这个新向量,我们并不认识。它大概率有毒,有点像蛇,隐约还带着“我”的意志。它处于一种似是而非、不可名状的状态。但这个“不可名状”的向量,理论上就包含了“蛇”这个词本身,以及它在“我用毒毒毒蛇”这句话中所有的上下文关系。
总结
刚刚我们讲的整个过程,就是一个AttentionHead(注意力头)的工作流程。多头注意力机制(Multi-HeadAttention),就是把这个过程并行执行N次。每个Attention结构都有不同的关注点(有的关注语法,有的关注指代,有的关注特定实体)。最后,我们将所有版本的“我用毒毒毒蛇”拼接在一起,再次经过线性层融合。输入是句子中每个词的Embedding,输出是混合了不同关注点之后的一种全局的混沌形式。而这个形式又会继续被当做下一层Attention的输入。这个过程重复几十次,最终就在这一片混沌中演化出了智能。
我们亲手写下了每一行公式,却读不懂它在想什么。这常常让我想起仰望星空的感觉。宇宙如此浩瀚,规则如此深邃,我们这群困于时空的碳基生物,真的有能力彻底理解它吗?也许不能。但这又有什么关系呢?让人类着迷的从来不是“我终于搞懂了”,而是“原来还有这么多不懂”值得去探索。正是因为不懂,才要去懂。这大概就是属于科学的浪漫。